Linux网络编程
Linux网络编程
首先要知道 Linux设计哲学: 一切皆文件
我的github仓库 RareVoyager/RareVoyager_linux_network_programming: Linux Cpp 编程学习
Day 1
1 | // @brief: 创建一个套接字 |
TCP服务器通信流程分析 :
1 | 服务器 客户端 |
最后的close() 用shutdown() 会更好一些,可指定关闭发送或接收方向,避免数据丢失。
1 | // 服务端代码 |
1 | // 客户端代码 |
最终效果

Day 2
TCP协议三次握手:
主动发起连接请求端,发送SYN标志位,请求建立连接,携带数据包号,数据字节数,滑动窗口大小。
被动接受连接请求,发送ACK标志位,同时携带SYN请求标志位,携带序号 ,数据字节数(0),滑动窗口大小。
主动发起连接请求,发送ACK标志位,应答服务器连接请求,携带确认序号
四次挥手:
主动关闭连接请求,发送FIN标志位。
被动关闭连接请求端,应答ACK标志位 — 半关闭完成
被动关闭连接请求 ,发送FIN标志位
主动关闭连接请求,应答ACK标志位
滑动窗口:
发送给连接对端,本端的缓冲区大小(实时),保证数据不会丢失
结合TCP状态转换图以及TCP通讯时序图来理解三次握手和四次挥手流程
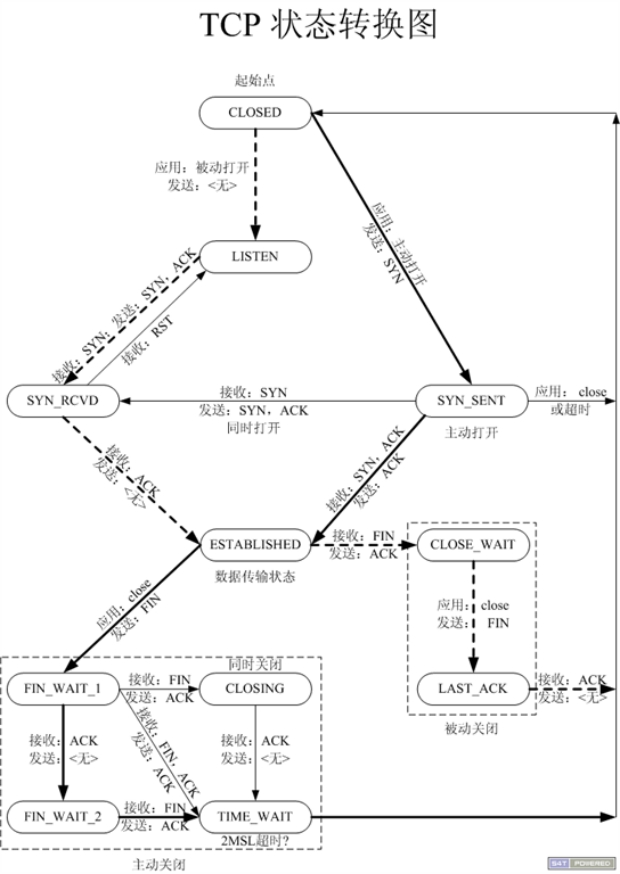
CLOSED:表示初始状态。
LISTEN:该状态表示服务器端的某个SOCKET处于监听状态,可以接受连接。
SYN_SENT:这个状态与SYN_RCVD遥相呼应,当客户端SOCKET执行CONNECT连接时,它首先发送SYN报文,随即进入到了SYN_SENT状态,并等待服务端的发送三次握手中的第2个报文。SYN_SENT状态表示客户端已发送SYN报文。
SYN_RCVD: 该状态表示接收到SYN报文,在正常情况下,这个状态是服务器端的SOCKET在建立TCP连接时的三次握手会话过程中的一个中间状态,很短暂。此种状态时,当收到客户端的ACK报文后,会进入到ESTABLISHED状态。
ESTABLISHED:表示连接已经建立。
FIN_WAIT_1: FIN_WAIT_1和FIN_WAIT_2状态的真正含义都是表示等待对方的FIN报文。区别是:
FIN_WAIT_1状态是当socket在ESTABLISHED状态时,想主动关闭连接,向对方发送了FIN报文,此时该socket进入到FIN_WAIT_1状态。
FIN_WAIT_2状态是当对方回应ACK后,该socket进入到FIN_WAIT_2状态,正常情况下,对方应马上回应ACK报文,所以FIN_WAIT_1状态一般较难见到,而FIN_WAIT_2状态可用netstat看到。
FIN_WAIT_2:**主动关闭链接的一方,发出FIN收到ACK以后进入该状态**。称之为半连接或半关闭状态。该状态下的socket只能接收数据,不能发。
TIME_WAIT: 表示收到了对方的FIN报文,并发送出了ACK报文,等2MSL后即可回到CLOSED可用状态。如果FIN_WAIT_1状态下,收到对方同时带 FIN标志和ACK标志的报文时,可以直接进入到TIME_WAIT状态,而无须经过FIN_WAIT_2状态。
CLOSING: 这种状态较特殊,属于一种较罕见的状态。正常情况下,当你发送FIN报文后,按理来说是应该先收到(或同时收到)对方的 ACK报文,再收到对方的FIN报文。但是CLOSING状态表示你发送FIN报文后,并没有收到对方的ACK报文,反而却也收到了对方的FIN报文。什么情况下会出现此种情况呢?如果双方几乎在同时close一个SOCKET的话,那么就出现了双方同时发送FIN报文的情况,也即会出现CLOSING状态,表示双方都正在关闭SOCKET连接。
CLOSE_WAIT: 此种状态表示在等待关闭。当对方关闭一个SOCKET后发送FIN报文给自己,系统会回应一个ACK报文给对方,此时则进入到CLOSE_WAIT状态。接下来呢,察看是否还有数据发送给对方,如果没有可以 close这个SOCKET,发送FIN报文给对方,即关闭连接。所以在CLOSE_WAIT状态下,需要关闭连接。
LAST_ACK: 该状态是被动关闭一方在发送FIN报文后,最后等待对方的ACK报文。当收到ACK报文后,即可以进入到CLOSED可用状态。
半关闭
当TCP链接中A发送FIN请求关闭,B端回应ACK后(A端进入FIN_WAIT_2状态),B没有立即发送FIN给A时,A方处在半链接状态,此时A可以接收B发送的数据,但是A已不能再向B发送数据。
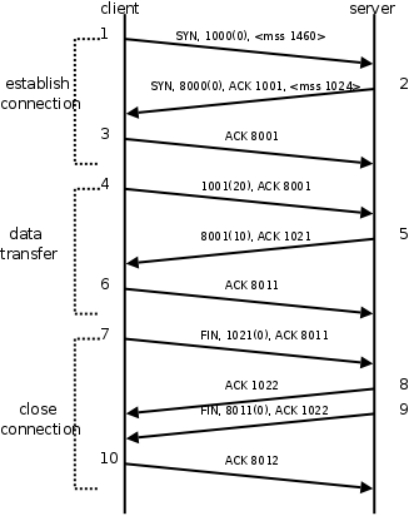
建立连接(三次握手)的过程:
- 客户端发送一个带SYN标志的TCP报文到服务器。这是三次握手过程中的段1。
客户端发出段1,SYN位表示连接请求。序号是1000,这个序号在网络通讯中用作临时的地址,每发一个数据字节,这个序号要加1,这样在接收端可以根据序号排出数据包的正确顺序,也可以发现丢包的情况,另外,规定SYN位和FIN位也要占一个序号,这次虽然没发数据,但是由于发了SYN位,因此下次再发送应该用序号1001。mss表示最大段尺寸,如果一个段太大,封装成帧后超过了链路层的最大帧长度,就必须在IP层分片,为了避免这种情况,客户端声明自己的最大段尺寸,建议服务器端发来的段不要超过这个长度。
- 服务器端回应客户端,是三次握手中的第2个报文段,同时带ACK标志和SYN标志。它表示对刚才客户端SYN的回应;同时又发送SYN给客户端,询问客户端是否准备好进行数据通讯。
服务器发出段2,也带有SYN位,同时置ACK位表示确认,确认序号是1001,表示“我接收到序号1000及其以前所有的段,请你下次发送序号为1001的段”,也就是应答了客户端的连接请求,同时也给客户端发出一个连接请求,同时声明最大尺寸为1024。
- 客户必须再次回应服务器端一个ACK报文,这是报文段3。
客户端发出段3,对服务器的连接请求进行应答,确认序号是8001。在这个过程中,客户端和服务器分别给对方发了连接请求,也应答了对方的连接请求,其中服务器的请求和应答在一个段中发出,因此一共有三个段用于建立连接,称为“三方握手(three-way-handshake)”。在建立连接的同时,双方协商了一些信息,例如双方发送序号的初始值、最大段尺寸等。
数据传输的过程:
- 客户端发出段4,包含从序号1001开始的20个字节数据。
- 服务器发出段5,确认序号为1021,对序号为1001-1020的数据表示确认收到,同时请求发送序号1021开始的数据,服务器在应答的同时也向客户端发送从序号8001开始的10个字节数据,这称为piggyback。
- 客户端发出段6,对服务器发来的序号为8001-8010的数据表示确认收到,请求发送序号8011开始的数据。
在数据传输过程中,ACK和确认序号是非常重要的,应用程序交给TCP协议发送的数据会暂存在TCP层的发送缓冲区中,发出数据包给对方之后,只有收到对方应答的ACK段才知道该数据包确实发到了对方,可以从发送缓冲区中释放掉了,如果因为网络故障丢失了数据包或者丢失了对方发回的ACK段,经过等待超时后TCP协议自动将发送缓冲区中的数据包重发。
关闭连接(四次握手)的过程:
由于TCP连接是全双工的,因此每个方向都必须单独进行关闭。这原则是当一方完成它的数据发送任务后就能发送一个FIN来终止这个方向的连接。收到一个 FIN只意味着这一方向上没有数据流动,一个TCP连接在收到一个FIN后仍能发送数据。首先进行关闭的一方将执行主动关闭,而另一方执行被动关闭。
- 客户端发出段7,FIN位表示关闭连接的请求。
- 服务器发出段8,应答客户端的关闭连接请求。
- 服务器发出段9,其中也包含FIN位,向客户端发送关闭连接请求。
- 客户端发出段10,应答服务器的关闭连接请求。
建立连接的过程是三方握手,而关闭连接通常需要4个段,服务器的应答和关闭连接请求通常不合并在一个段中,因为有连接半关闭的情况,这种情况下客户端关闭连接之后就不能再发送数据给服务器了,但是服务器还可以发送数据给客户端,直到服务器也关闭连接为止。
\OSI七层模型**
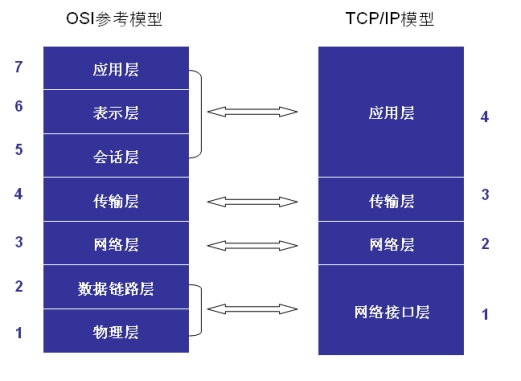
OSI模型
- 物理层:主要定义物理设备标准,如网线的接口类型、光纤的接口类型、各种传输介质的传输速率等。它的主要作用是传输比特流(就是由1、0转化为电流强弱来进行传输,到达目的地后再转化为1、0,也就是我们常说的数模转换与模数转换)。这一层的数据叫做比特。
- 数据链路层:定义了如何让格式化数据以帧为单位进行传输,以及如何让控制对物理介质的访问。这一层通常还提供错误检测和纠正,以确保数据的可靠传输。如:串口通信中使用到的115200、8、N、1
- 网络层:在位于不同地理位置的网络中的两个主机系统之间提供连接和路径选择。Internet的发展使得从世界各站点访问信息的用户数大大增加,而网络层正是管理这种连接的层。
- 传输层:定义了一些传输数据的协议和端口号(WWW端口80等),如:TCP(传输控制协议,传输效率低,可靠性强,用于传输可靠性要求高,数据量大的数据),UDP(用户数据报协议,与TCP特性恰恰相反,用于传输可靠性要求不高,数据量小的数据,如QQ聊天数据就是通过这种方式传输的)。 主要是将从下层接收的数据进行分段和传输,到达目的地址后再进行重组。常常把这一层数据叫做段。
- 会话层:通过传输层(端口号:传输端口与接收端口)建立数据传输的通路。主要在你的系统之间发起会话或者接受会话请求(设备之间需要互相认识可以是IP也可以是MAC或者是主机名)。
- 表示层:可确保一个系统的应用层所发送的信息可以被另一个系统的应用层读取。例如,PC程序与另一台计算机进行通信,其中一台计算机使用扩展二一十进制交换码(EBCDIC),而另一台则使用美国信息交换标准码(ASCII)来表示相同的字符。如有必要,表示层会通过使用一种通格式来实现多种数据格式之间的转换。
- 应用层:是最靠近用户的OSI层。这一层为用户的应用程序(例如电子邮件、文件传输和终端仿真)提供网络服务。
Day 3
TCP状态时序图:
1. 主动发起连接请求端:CLOSE -- 发送SYN -- SEND_SYN -- 接收 ACK、SYN -- SEND_SYN -- 发送 ACK -- ESTABLISHED(数据通信态)
主动关闭连接请求端: ESTABLISHED (数据通信态) — 发送FIN — FIN_WAIT_1 — 接收ACK — FIN_WAIT_2(半关闭)
—接收对端发送 FIN—FIN_WAIT_2(半关闭)—回发ACK —TIME_WAIT(只有主动关闭的一方才会经理这个状态)—等 2MSL时长—SLOSE
被动接收连接请求端:CLOSE —LISTEN— 接收 SYN —LISTEN —发送ACK、SYN— SYN_RCVD —接收ACK—ESTABLISHED(数据通信态)
被动关闭连接请求端:ESTABLISHED(数据通信态)—接收FIN—ESTABLISHED(数据通信态)—发送ACK
—CLOSE_WAIT(说明对端【主动关闭连接端】处于半关闭状态)—发送FIN—LAST_ACK—接收ACK—CLOSE2MSL时长:一定出现在【主动关闭连接请求端】。—-对应TIME_VAIT状态。
保证,最后一个ACK能成功被对端接收。(等待期间,对端没收到我发的ACK,对端会再次发送FIN请求。)
端口复用:半关闭: 通信双方中,只有一端通信关闭 — FIN_WAIT_2
端口复用函数
1 | int opt = 1: |
上述服务器是单线程,需要手动写多线程连接或一对一开启C/S。
响应式 — 多路IO转接
select:
1 | // select 函数应用 |
使用:
1 | lfd = socket(); |
select优缺点:
缺点: 监听上限受文件描述符限制,最大为1024
检测满足条件的fd,自己添加业务逻辑提高效率,提高了编码难度
优点: 跨平台完成文件描述符监听
poll
1 | /** |
突破1024 文件描述符限制
cat /proc/sys/fs/file-max: 当前计算机能打开的文件最大个数,受硬件影响
ulimit -a: 当前用户进程下,默认打开文件描述符个数
修改:
soft nofile 65536: 设置默认值,可以借助命令修改 ulimit -n
hard nofile 100000: 设置上限
epoll : 本质是一颗平衡二叉树(红黑树)
1 | /** |
ET 和 LT:
ET: 边缘触发 高效模式,但是只支持非阻塞,状态变化时通知一次
1 | struct epoll_event event; |
优点: 高效,突破1024限制
缺点: 不能跨平台,
LT: 水平触发(默认),有数据就一直通知
epoll反应堆模型:epoll ET模式 + 非阻塞 + void *ptr
原来: socket、bind、listen — epoll_create 创建监听 红黑树 —> 返回 epfd —> epoll_ctl() 向树上添加—个监听fd — while (true) —>
—> epoll_wait 监听 — 对应监听fd有事件产生 — 返回 监听满足数组。 — 判断返回数组元素 — lfd满足 — Accept — cfd 满足read()
— 小->大 — write回去。
反应堆:不但要监听 cfd 的读事件、还要监听cfd的写事件。 I
socket、bind、listen — epoll_create 创建监听 红黑树 — 返回 epfd — epoll_ctl() 向树上添加—个监听fd — while (true) —
epoll_wait 监听 — 对应监听fd有事件产生 — 返回 监听满足数组。 — 判断返回数组元素 — lfd满足 — Accept — cfd 满足
-read()—-小->大—cfd从监听红黑树上摘下—EPOLLOUT—回调函数—epoll_ctl()—EPOLL_CTL_ADD重新放到红黑上监听写事件
— 等待 epoll_wait 返回 — 说明 cfd 可写 — write回去 — cfd从监听红黑树上摘下 — EPOLLIN
epoll_ctl() — EPOLL_CTL_ADD 重新放到红黑上监听读事件 — epoll_wait 监听
1 | ┌──────────────────────────────┐ |
select, poll, epoll 对比图
| 维度 | select | poll | epoll |
|---|---|---|---|
| 基本思路 | 每次把 fd 集合拷给内核扫描 | 每次把 pollfd[] 拷给内核扫描 |
注册一次 fd,内核维护就绪队列 |
| 数据结构 | fd_set 位图 |
struct pollfd[] 数组 |
内核红黑树/哈希 + 就绪链表(实现细节) |
| 事件获取方式 | 全量扫描 0..maxfd | 全量扫描 整个数组 | 只返回就绪的 N 个 |
| 时间复杂度(典型) | O(maxfd) | O(nfds) | 约 O(1) ~ O(就绪数) |
| fd 上限 | 有限(FD_SETSIZE,常见 1024,可改但麻烦) | 理论上更大(受系统 fd 限制) | 理论上更大(受系统 fd 限制) |
| 每次调用开销 | 需要重置/重建 fd_set;用户态↔内核态拷贝 |
用户态↔内核态拷贝 pollfd[] |
epoll_ctl 增删改一次;epoll_wait 返回就绪列表 |
| 是否能知道“哪些就绪” | 需要自己从位图里找 | 需要遍历数组看 revents |
直接给你就绪事件数组 |
| 触发模式 | 只有水平触发(LT) | 只有水平触发(LT) | 支持 LT / ET(边缘触发) |
| 适合连接数 | 少量 | 中等 | 大量(高并发) |
| 可移植性 | POSIX 广泛支持(跨平台) | POSIX 广泛支持 | Linux 特有(BSD/macOS 用 kqueue) |
| 编程舒适度 | 最老、接口绕、坑多 | 比 select 好用 | 最灵活但也更容易踩 ET/非阻塞的坑 |
| 典型使用场景 | 简单工具、小规模并发 | 兼容性要求高、规模不大 | Linux 高性能服务器(Reactor) |
Day5 线程池
TCP通信和UDP通信各自的优缺点:
TCP:
面向连接的,可靠数据包传输。对于不稳定的网络层,采取完全弥补的通信方式。丢包重传。
优点:
稳定。
数据流量稳定、速度稳定、顺序
缺点:
传输速度慢。相率低。开销大。
使用场景:数据的完整型要求较高,不追求效率。大数据传输、文件传输。
UDP:
无连接的,不可靠的数据报传递。对于不稳定的网络层,采取完全不弥补的通信方式。默认还原网络状况
优点:
传输速度块。相率高。开销小。
缺点:
不稳定。数据流量速度。顺序。
使用场景:对时效性要求较高场合。稳定性其次。游戏、视频会议、视频电话。
UDP实现的C/S模型:
1 | // recv() / send() 替代tcp通信 |
本地套接字:
sockaddr_in —> sockaddr_un
源码包安装
源码包安装:
# 先拉取代码
git clone https://github.com/libevent/libevent.git
# 进入到目录
cd libevent
# 切换分支
git checkout release-2.1.8-stable
# 验证一下
git branch
---------------------也可以一步到位--------------------
git clone -b release-2.1.8-stable https://github.com/libevent/libevent.git
./configure 检查安装环境生成makefile
make 生成.。和可执行文件
sudo make install 将必要的资源c置系统指定目录。
进入sample 验证安装
基于事件的异步通信模型:
libevent框架: 创建 event_base
struct event_base event_base_new(void) :
struct event_base base = event_base_new() :
创建事件evnet
常规事件 event—>event_new():
bufferevent —> bufferevent_socket_new():
将事件添加到base上
int event_add(struct event ev, const struct timeval tv)
循环监听事件满足
int event_base_dispatch(struct event_base *base):
event_base_dispatch(base) :
释放 event_base
event_base_free(base) :
事件的未决和非未决:
未决:有资格被处理,但还没有被处理。非未决:没有资格被处理。
bufferevent:
读缓存
写缓冲
相关函数:
1 | /** |
Libevent实现TCP 服务器流程
1 | 1. 创建 event_base |
Libevent实现TCP客户端流程
1 | 1. 创建 event_base |


